Kääntäjien työkalut
1.3.2023 | Henry Laine

Teknologian kehittyminen viimeisten vuosikymmenten aikana on mullistanut kääntäjän työn. Kirjoituskoneista on siirrytty tietokoneisiin, ja monet fyysiset aineistot, kuten sanakirjat, ovat korvautuneet sähköisillä. Kääntämisestä onkin tullut yhä teknisempää, kun kääntäjien on pitänyt oppia uusien sähköisten työkalujen käyttö. Heidän myös pitää seurata kehitystä, jotta he eivät vahingossa jää siitä jälkeen.
Vanhat, uudistuneet työkalut
Kääntäjien klassisiin työkaluihin kuuluvat sanakirjat, kielioppi- ja kielenhuoltoteokset sekä rinnakkaistekstit. Näitä on vieläkin saatavilla painetussa muodossa, mutta todennäköisesti useimmat kääntäjät suosivat sähköisiä versioita. Esimerkiksi jonkin tietyn sanan etsiminen on tuhat kertaa nopeampaa sähköisestä sanakirjasta kuin paperille painetusta.
Sanakirjat
Kääntäminen on sanojen kanssa työskentelyä. Kääntäjän on ymmärrettävä sanojen merkitykset ja etsittävä sanoille erikielisiä vastineita. Kääntämisessä onkin paljon apua sanakirjoista, jotka voidaan jakaa kahteen päätyyppiin: kaksikielisiin ja yksikielisiin.
Kaksikieliset sanakirjat ilmentävät erikielisten sanojen vastaavuussuhteita. Yksinkertaisimmillaan tällainen sanakirja voi sisältää hakusanan yhdellä kielellä (esim. suomi) ja sen vastineen toisella kielellä (esim. englanti). Sanakirjan laajuudesta ja käyttötarkoituksesta riippuen sanakirjassa voi myös olla sanaa koskevaa muuta tietoa, esimerkiksi käyttöesimerkkejä, taivutusohjeita tai sanoja, joilla on läheinen merkitys.
Kääntäjän näkökulmasta yksinkertaiset kaksikieliset sanakirjat eivät ole kovin hyödyllisiä, sillä niissä ei ole tarpeeksi tietoa sanojen käyttöympäristöistä. Jos sanakirjassa jollekin sanalle on annettu esimerkiksi kolme vastinetta eikä muuta tietoa, kääntäjän on hyvin vaikea arvioida, mikä niistä kävisi omaan tekstiin.
Kääntäjällä pitäisi olla jo runsas sanavarasto niin omalla kuin vieraalla kielellä, joten hänen ei todennäköisesti kovinkaan usein tarvitse turvautua yleiskielisiin sanakirjoihin. Tämän takia yksinkertaiset kaksikieliset sanakirjat toimivat ennemminkin muistin apuvälineinä, jos kääntäjä tietää oikean vastineen mutta se ei juuri sillä hetkellä tule mieleen.
Kaksikielisistä sanakirjoista on sitä enemmän hyötyä, mitä tarkemmin ne keskittyvät käännettävän tekstin aiheeseen. Esimerkiksi lääketieteen sanoille eli termeille on olemassa vakiintuneet vastineet useissa kielissä, joten vastineita kannattaa etsiä juuri lääketieteen sanakirjoista. Näissä myös on käsitteille tarkat määritelmät, jotka helpottavat ymmärtämään tekstin asiasisältöä.
Kaksikielisten sanakirjojen lisäksi on olemassa myös yksikielisiä sanakirjoja. Niissä on hakusanoja ainoastaan yhdellä kielellä, mutta yleensä niissä on kaksikielisiin sanakirjoihin verrattuna paljon enemmän tietoa sanoista ja niiden käytöstä. Määritelmän lisäksi yksikielisessä sanakirjassa voi mm. olla esimerkkejä, käyttösuosituksia ja etymologisia selityksiä.
Koska yksikieliset sanakirjat on nimensä mukaisesti kirjoitettu yhdellä kielellä, ne on tarkoitettu henkilöille, jotka ymmärtävät ainakin kohtalaisesti kirjan kieltä. Kääntäjät kuuluvat tähän ryhmään, mutta he todennäköisesti hyötyvät enemmän yksikielisistä sanakirjoista, jotka käsittelevät jotain vierasta kieltä. Vieraan kielen ymmärtäminen tai kyseiseen kieleen kääntäminen on aina haastavampaa kuin vastaava toiminta omalla äidinkielellä. Yksikielisestä sanakirjasta voi esimerkiksi tarkistaa, miten jokin sana taipuu tai minkälainen partikkeli kuuluu sanan kanssa yhteen.
Sekä painetussa että sähköisessä muodossa on olemassa paljon erilaisia sanakirjoja. Yksikielisistä sanakirjoista voi mainita Kielitoimiston sanakirjan, joka sisältää suomen sanojen lisäksi esimerkkejä ja taivutusohjeita. Ruotsin kielen sanoille löytyy Ruotsin akatemian ylläpitämä sivusto svenska.se, jossa voi tehdä hakuja useampaan sanakirjaan samanaikaisesti. Englannin kielen sanoja voi puolestaan etsiä esimerkiksi amerikanenglantiin keskittyvästä Merriam-Webster's Dictionarysta tai brittienglantiin keskittyvästä Cambridge Dictionarysta.

Svenska.se-sivuston sanakirjoista löytyneet tulokset hakusanalla "korpus"
Kielioppiteokset ja kielenhuolto-oppaat
Kääntämisessä on tunnettava eri kielten kieliopit ja oikeinkirjoitussäännöt. Yleiskielisiä tai ammattikielisiä tekstejä kääntävä hyötyy erityisesti kahdenlaisista oppaista, jotka käsittelevät kieltä ja sen käyttöä: kielioppiteoksista ja kielenhuolto-oppaista.
Kielioppiteokset ovat nykyään deskriptiivisiä. Niiden laatimisen lähtökohtana on autenttisen kielenkäytön tarkkailu, joka mahdollistaa jonkin kielen säännöstön kuvailemisen. Suomalaisessa kielioppiteoksessa voidaan esittää esimerkiksi se, miten astevaihtelu toimii ja mitä sanoja se koskee. Vastaavassa ruotsalaisessa teoksessa voidaan puolestaan käsitellä esimerkiksi pää- ja sivulauseen sanajärjestyksiä.
Kääntäjä hyötyy enemmän vieraan kielen kielioppiteoksista, sillä vieraan kielen puhujille ei muodostu yhtä vahvaa sisäistä kielioppia kuin natiivipuhujille. Tämä on erittäin olennaista vieraaseen kieleen käännettäessä, sillä lukijat odottavat, että kääntäjän kieli on kieliopiltaan oikeaoppista. Toisaalta myös natiivipuhujat voivat hyödyntää kielioppiteoksia. Monille suomalaisille on esimerkiksi hankala suomen kielen potentiaalirakenne, jonka muodostussäännöt voi tarkistaa kielioppiteoksesta.
Jokaiselle kielelle on yleensä julkaistu ainakin yksi kielioppiteos, joka on ns. auktoritatiivinen. Suomelle löytyy Iso suomen kielioppi, joka on vapaasti verkossa saatavilla. Ruotsille löytyy Svenska Akademiens grammatik, joka sekin on verkossa saatavilla. Englannille löytyy useampi teos, esimerkiksi Oxford Modern English Grammar.
Kielioppisääntöjen lisäksi kääntäjän täytyy hallita eri kielten oikeinkirjoitusta koskevat säännöt. Näiden omaksumisessa auttavat kielenhuolto-oppaat. Kielioppiteoksiin verrattuna kielenhuolto-oppaat ovat puhtaasti normatiivisia, sillä ne pyrkivät sanelemaan kielenkäyttäjälle sääntöjä, joita hänen tulisi noudattaa.
Jokaisen kielen oikeinkirjoitussäännöt ovat ainakin osittain erilaiset. Suomessa esimerkiksi suositetaan vahvasti sitä, että pää- ja sivulause erotetaan pilkulla. Ruotsissa on vastaava mutta löysempi sääntö: päälauseen lopussa olevaa sivulausetta ei usein pilkuteta, mutta jos sivulause aloittaa päälauseen, sivulauseen ja päälauseen väliin lisätään pilkku. Englannin pilkutussäännöt ovat vielä löysempiä, sillä englannin oikeinkirjoitussäännöt eivät ole yhtä kivettyneitä. Esimerkiksi eri julkaisijoiden välillä on eroja siinä, minkälaiset oikeinkirjoitussäännöt ovat ihanteena.
Oikeinkirjoitukseen liittyvissä kysymyksissä suomalaiset voivat konsultoida Kielitoimiston ohjepankkia, joka on vapaasti Internetissä saatavilla. Lisäksi kielenhuollon tiedotuslehdessä Kielikellossa on julkaistu runsaasti hyödyllisiä artikkeleita, jotka käsittelevät suomen oikeinkirjoitusta. Ruotsin oikeinkirjoituksen kohdalla hyvä opas on Svenska skrivregler, jossa käsitellään mm. välimerkkejä, lyhenteitä ja yhdyssanoja. Englanninkielisiä kielenhuolto-oppaita on puolestaan olemassa useita. Esimerkiksi Chicago Manual of Style koskee amerikanenglantia, kun taas New Oxford Style Manual kattaa brittienglannin.
Rinnakkaistekstit
Käännös on ihanteellinen silloin, kun se ei eroa vastaavista, alkujaan kohdekielellä kirjoitetuista teksteistä. Tällaiset tekstit eli rinnakkaistekstit ovat kääntämisessä hyödyllisiä, sillä ne havainnollistavat, minkälaisiin käännöksiin pitäisi pyrkiä.
Rinnakkaistekstejä voi kääntämisessä hyödyntää monella tavalla. Jos käännettävä teksti esimerkiksi käsittelee jotain erikoisalaa, rinnakkaistekstejä lukemalla voi sisäistää alan tietoa. Rinnakkaistekstejä voi myös käyttää kääntämistä tukevassa termityössä, jossa kääntäjä metsästää rinnakkaistekstien avulla vastineita lähdetekstin termeille. Näiden käyttötarkoitusten lisäksi rinnakkaistekstit havainnollistavat lähde- ja kohdetekstien eroja esimerkiksi tyylin, rekisterin ja konventioiden osalta.
Muihin työkaluihin verrattuna rinnakkaistekstien käyttö vaatii paljon työtä kääntäjältä. Sopivat rinnakkaistestit on ensin löydettävä tekstimassojen seasta. Nykyisin tämä on onneksi nopeampaa Internetin ansiosta. Kuitenkin läheskään kaikkia tekstejä ei ole digitoitu, joten kääntäjä voi joskus joutua etsimään rinnakkaistestejä myös painetuista lähteistä.
Kun kääntäjä on löytänyt riittävän määrän rinnakkaistekstejä, hänen on vielä jaksettava lukea ne läpi. Jos teksti käsittelee monimutkaista tai kääntäjälle tuntematonta aihetta, tekstin lukemiseen ja ymmärtämiseen voi kulua merkittävästi aikaa. Toisinaan tekstiä ei tarvitse lukea kokonaan, jolloin riittää, että kääntäjä silmäilee tärkeimmät kohdat. Esimerkiksi oikean tyylin ja rekisterin omaksuu melko lyhyestäkin tekstipätkästä.
Vaikka rinnakkaistekstien käyttö on työlästä, niiden avulla voi parantaa käännöksen laatua. Tekstejä lukemalla kääntäjä myös omaksuu uutta tietoa, mikä tekee muiden samanlaisten tekstien kääntämisen helpommaksi tulevaisuudessa.
Uudet työkalut
Kääntäjien uudet työkalut kulkevat käsi kädessä tietotekniikan kehittymisen kanssa. Ilman tietokoneita eivät olisi mahdollisia sellaiset sovellukset kuin käännösmuistiohjelmat, korpukset ja konekääntimet.
Käännösmuistiohjelmat
Käännösprosessin kannalta ehkä tärkeimmäksi uudeksi innovaatioksi on muodostunut käännösmuistiohjelma. Se on nimensä mukaisesti tietokoneella ajettava ohjelma, joka muistuttaa ominaisuuksiltaan tekstinkäsittelyohjelmaa. Molemmissa ohjelmatyypeissä kääntäjä pystyy kirjoittamaan ja muokkaamaan tekstiä. Erona on kuitenkin se, että käännösmuistiohjelmassa näkyvillä on sekä käännettävä teksti että työstettävä käännös. Käännösmuistiohjelma myös pyrkii automaattisesti säilyttämään lähdetekstin asettelun, jolloin lähde- ja kohdetekstien pitäisi näyttää ulkonäön kannalta identtisiltä (fontit, fonttikoot, rivivälit jne.).
Käännösmuistiohjelmien keskeisimpiin ominaisuuksiin lukeutuu tekstin segmentointi. Ohjelma jakaa lähdetekstin automaattisesti virkkeisiin, jotka kääntäjä voi sitten yksi kerrallaan kääntää kohdekielelle. Ohjelmasta riippuen lähde- ja kohdeteksti on aseteltu joko vierekkäin tai päällekkäin, jolloin kääntäjä voi helposti seurata, mikä lähdetekstin segmentti vastaa mitäkin kohdetekstin segmenttiä ja mitkä segmentit ovat vielä kääntämättä.
Toinen keskeinen ominaisuus on käännösmuistiohjelman nimessäkin esiintyvä käännösmuisti. Se on eräänlainen monikielinen korpus, joka sisältää tekstisegmenttejä lähdekielellä ja yhdellä tai useammalla kohdekielellä. Käännösmuisti syntyy automaattisesti, kun tekstiä käännetään käännösmuistiohjelmalla. Käännösmuistin tunnistaa .tmx-tiedostopäätteestä (Translation Memory eXchange).
Käännösmuistin tarkoitus on nopeuttaa ja helpottaa kääntämistä, koska kääntäjän ei tarvitse kääntää samaa segmenttiä kahteen kertaan. Kun uusi teksti syötetään käännösmuistiohjelmaan, ohjelma tarkistaa, vastaako jokin lähdetekstin segmentti käännösmuistiohjelmasta löytyvää segmenttiä. Ohjelma osaa myös arvioida, kuinka läheisesti löytynyt segmentti vastaa käännettävää segmenttiä. Vastaavuus ilmaistaan prosenttilukuna: vastaavat täydellisesti (100 %), vastaavat lähestulkoon (99–75 %) tai vastaavat vain osittain (50–74 %). Kääntäjä voi sitten päättää, siirtääkö hän tarjotun segmentin suoraan käännökseen, muokkaako hän sitä vai jättääkö hän sen kokonaan huomioimatta.
Käännösmuistista on sitä enemmän hyötyä, mitä läheisemmin muistiin lisätyt tekstit muistuttavat uutta käännettävää tekstiä. Jos sekä käännettävä teksti että muistiin lisätyt tekstit käsittelevät esimerkiksi kuorma-autojen jarrujärjestelmiä, käännösmuistista löytyy todennäköisesti segmenttejä, jotka ovat tyyliltään ja termistöltään yhteensopivia työstettävän tekstin kanssa.
Käännösmuisteista on myös erityisen paljon hyötyä silloin, kun käännetään vanhojen tekstien uusia versioita. Esimerkiksi jostain tieteellisestä teoksesta on voitu julkaista uudistettu painos, joka osittain vastaa vanhaa painosta. Tällöin käännösmuisti varmistaa, ettei kääntäjä vahingossa tee turhaa työtä ja käännä samoja kohtia kahteen kertaan.
Käännösmuistiohjelman muita ominaisuuksia ovat termilistat, jotka voi integroida sovelluksen käyttöliittymään. Kääntäjä voi ennen kääntämistä tai sen aikana luoda listan, joka sisältää lähdekielisiä termejä sekä niiden kohdekielisiä vastineita. Termilistat toimivat hieman samalla tavalla kuin käännösmuistit. Jos jokin lähdetekstin segmentti sisältää termilistaan kuuluvan termin, ohjelma ilmoittaa tästä kääntäjälle ja näyttää termin vieraskielisen vastineen. Termilistat siis varmistavat, että samat lähdetekstin termit käännetään aina samoilla vastineille. Tämä on erityisesti hyödyllistä silloin, kun käännettä teksti on pitkä tai jos teksti on käännettävä useamman kääntäjän projektina.
Käännösmuistiohjelmista on paljon hyötyä, mutta samalla ne muodostavat kääntäjille ylimääräisen kuluerän. Kaupallisten ohjelmien (esim. memoQ, Wordfast ja Trados Studio) lisenssin hinta liikkuu 500 euron tuntumassa. Lisenssi on myös uudistettava muutaman vuoden välein, jos haluaa käyttää ohjelmien uusimpia versioita. Kaupallisten sovellusten lisäksi on olemassa myös ilmaisia, avoimen lähdekoodin käännösmuistiohjelmia. Näistä suosituin lienee OmegaT, jossa on toki kaikki keskeisimmät ominaisuudet mutta jonka käyttö voi vaatia hieman opettelua ja säätämistä.
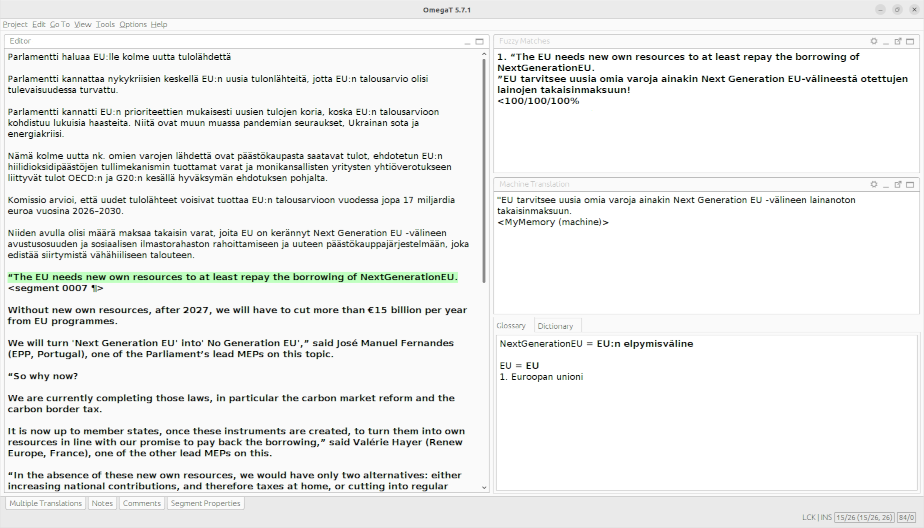
OmegaT-käännösmuistiohjelman käyttöliittymä, jossa on näkyvillä tekstinkäsittelijä, käännösmuisti, konekäännin ja termilista
Korpukset
Tietokoneiden kehittyminen on mahdollistanut suurten tekstimassojen kokoamisen yhdeksi elektroniseksi aineistoksi eli korpukseksi. Korpukset ovat tekstikokoelmia, jotka on koottu jostain tietystä lähtökohdasta. Korpukset voivat olla esimerkiksi yleiskielisiä, jolloin ne sisältävät hyvin laajan kirjon erilaisia tekstejä. Korpukset voivat myös olla kielenkäytöltään hyvin rajattuja, jolloin kokoamiskriteerit ovat tiukemmat. Tällaisia kriteerejä ovat mm. tekstien aihealue (esim. lääketiede tai tekniikka), tekstien julkaisuajankohta (esim. 1950-luvun tekstit) ja kirjoittajien tausta (esim. suomea vieraana kielenä puhuvat).
Korpusten ei tarvitse olla yksikielisiä, vaan niihin voidaan sisällyttää tekstejä ja niiden käännöksiä yhdestä tai useammasta kielestä. Itse asiassa edellisessä osiossa käsitellyt käännösmuistit ovat eräänlaisia monikielisiä korpuksia. Niitä syntyy automaattisesti, kun tekstiä käännetään käännösmuistiohjelman avulla. Monikielisiä korpuksia on myös mahdollista luoda vanhoista käännöksistä. Tällöin käännös ja sen lähdeteksti täytyy kuitenkin kohdistaa ensin eli varmistaa, että kohdetekstin segmentti (esim. kappale tai virke) vastaa juuri oikeaa lähdetekstin segmenttiä.
Korpuksia voi hyödyntää kääntäjän työssä monella eri tavalla. Yksikielisten korpusten avulla voi selvittää sanojen ja lausekkeiden käyttöä. Tästä on erityisen paljon hyötyä silloin, kun käännetään vieraaseen kieleen päin. Voidaan esimerkiksi selvittää, esiintyykö jokin ilmaus korpuksessa ja minkälainen on sen käyttökonteksti. Tämän tiedon perusteella kääntäjä voi sitten tehdä tietoisia käännösratkaisuja.
Monikielisten korpusten avulla voi etsiä käännösvastineita. Sanakirjoihin verrattuna tämä on tehokkaampaa, sillä korpus tarjoaa paljon tietoa vastineen käyttöympäristöstä. Vastine esiintyy osana kokonaista tekstiä, minkä ansiosta kääntäjän on helpompi arvioida, sopisiko löytynyt vastine myös omaan käännökseen.
Monikielisten korpusten kohdalla on hyvä huomioida, että niiden sisältämistä kielistä yksi tai useampi on ns. käännöskieltä. Käännöskieli on oikeaoppista kieltä, mutta siinä voi olla piirteitä, joita ei esiinny autenttisessa kielenkäytössä (eli teksteissä, jotka eivät ole käännöksiä). Usein nämä piirteet johtuvat lähdekielen vaikutuksesta. Kääntämisessä on kuitenkin ihanteena tuottaa tekstiä, joka muistuttaa mahdollisimman paljon kohdekielellä kirjoitettua autenttista tekstiä. Jos kääntäjä siis hyödyntää monikielistä korpusta käännösprosessissaan, hänen on oltava kriittisempi aineistoaan kohtaan.
Korpuksia voi hyödyntää muissakin vaiheissa kuin itse kääntämisessä. Yksi hyödyllinen korpustutkimuksellinen menetelmä on avainsana-analyysi. Sillä voi saada tietoa käännettävän tekstin aihepiiristä ilman, että tekstiä tarvitsee lukea itse alusta loppuun. Avainsana-analyysissä tekstiä verrataan korpuksen sisältämiin teksteihin. Näin saadaan selville avainsanat eli sanat, joita esiintyy tilastollisesti useammin analysoitavassa tekstissä kuin verrokkikorpuksessa. Avainsanat siis kertovat lyhyesti, mitä aihealuetta teksti käsittelee.

Tämän blogitekstin 22 ensimmäistä avainsanaa AntConc-korpusohjelman mukaan
Korpusohjelmia on olemassa sekä ilmaisia että maksullisia. Ilmaisista ohjelmista voi suositella AntConcia, josta löytyy kääntäjälle kaikki tarvittavat ominaisuudet. Kaupallisiin ohjelmiin puolestaan lukeutuu WordSmith Tools, joka on ehkä sopivampi todelliseen korpustutkimukseen. Nämä molemmat ohjelmat on tarkoitettu yksikielisille korpuksille. Monikieliset korpukset ovat usein käännösmuistimuodossa, joten niitä voi selata käännösmuistiohjelmilla (esim. ilmaisella OmegaT:llä).
Korpusaineistoja on runsaasti saatavilla Internetissä, mutta usein näitä ei pysty lataamaan omalle koneelle tekijänoikeudellisten syiden takia. Esimerkiksi Kielipankista löytyvistä korpuksista osan voi ladata itselle, kun taas osaa voi käyttää selaimella Korp-työkalun avulla. Kielipankissa on sekä yksi- että monikielisiä korpuksia. Toinen hyvä aineistolähde ovat Euroopan unionin käännösmuistit, jotka sisältävät käännöksiä esimerkiksi englannista suomeen ja ruotsiin.
Jos Internetistä ei tahdo löytyä oikeanlaista korpusta, korpuksen voi kasata myös itse. Korpuksen kasaaminen on yksinkertaista mutta työlästä. Esimerkiksi uutisartikkelikorpuksen voi kasata kopioimalla iltapäivälehtien sivuilta löytyviä artikkeleita yksi kerrallaan tekstitiedostoon. Korpus on kuitenkin sitä hyödyllisempi, mitä enemmän se sisältää sanoja, joten kohtuullisen kokoisen korpuksen (miljoonia sanoja) kasaaminen voi viedä oman aikansa.
Konekääntimet
Konekääntimet eivät ole mikään uusi keksintö, sillä niitä on yritetty kehittää jo 1950-luvulta alkaen. Ajan saatossa onkin kokeiltu erilaisia konekäännintyyppejä, kuten sääntöpohjaista ja tilastollista – tai jopa tyyppien yhdistelmiä. Uusimpana suuntauksena ovat neuroniverkkoihin eli tekoälyyn perustuvat konekääntimet.
Konekääntämisen suurimmaksi ongelmaksi on muodostunut käännösten laatu, sillä kehittyneimmätkään konekääntimet eivät pysty tuottamaan tekstiä, joka olisi varmasti julkaisukelpoista. Konekääntimillä on kuitenkin mahdollista tuottaa kelpoa tekstiä, jos joku ensin tarkistaa kääntimen tuotokset. Yleensä tämä henkilö on kääntäjä.
Käännösprosessissa konekääntämistä voi hyödyntää ainakin kahdella tavalla. Yksi näistä on ensin syöttää koko käännettävä teksti konekääntimeen ja sitten muokata kääntimen tuottamasta käännöksestä laadultaan julkaisukelpoinen. Tällöin puhutaan konekäännöksen jälkieditoinnista.
Konekääntimen tuottaman raakakäännöksen laatu vaikuttaa luonnollisesti siihen, kuinka järkevää on toteuttaa käännös jälkieditoinnin kautta. Jos alkulaatu on huonoa, kääntäjän on nopeampi kääntää koko teksti itse. Tällöin lopullinen käännöskin on todennäköisesti vastaavaa jälkieditoitua konekäännöstä parempi.
Järkevämpi tapa hyödyntää konekääntämistä on rinnastaa konekäännökset käännösmuisteihin. Jos jollekin segmentille ei löydy omasta käännösmuistista tarpeeksi läheistä vastinesegmenttiä, kääntäjä voi syöttää lähdetekstin segmentin konekääntimeen. Tällöin kääntäjä voi arvioida, onko konekäännös hyvä sellaisenaan, pitääkö sitä ensin muokata vai voiko siitä muuten hakea inspiraatiota omaan käännökseen esimerkiksi yksittäisten sanojen tai termien osalta. Vaikka konekäännöstä ei voisi millään tavalla hyödyntää, konekäännöksen pyytäminen ei vie merkittävästi aikaa, sillä monissa käännösmuistiohjelmissa tämä toiminto on integroitu suoraan käyttöliittymään.
Jos kääntäjä päättää hyödyntää konekääntimiä, hänen on oltava erityisen varovainen salassa pidettävän materiaalin kanssa. Konekääntimet sijaitsevat kolmannen osapuolen palvelimilla, joille lähdeteksti on pakko lähettää konekäännöstä varten. Lähdetekstin sisältö tulee siis ainakin konekäännöspalvelua tarjoavan tahon tietoon. Lisäksi palvelun tarjoaja voi käyttää lähdetekstiä ja konekäännöstä esimerkiksi kääntimen jatkokehittämiseen. Pahimmassa tapauksessa konekääntimeen syötetty teksti voi näkyä kääntimen muille käyttäjille.
Huomisen työkalut
Vaikka uudet työkalut ovat nopeuttaneet kääntäjän työtä, ne eivät ole oikeastaan hyödyttäneet kääntäjiä taloudellisesti. Kääntäjien odotetaan kääntävän yhä nopeammin ja tuottavan parempilaatuista tekstiä. Nykyisin ainakin käännösmuistiohjelma täytyy löytyä jokaisen asiatekstikääntäjän työkalupakista. Sähköisten käännöstyökalujen käytöstä onkin käytännössä tullut uusi normi käännösalalla.
Konekääntimien kehitys on merkittävä uhka kääntämiselle sen nykymuodossa. Välietappina voidaan mainita konekäännösten jälkieditoijan tehtävänimike, josta on tulossa yhä yleisempi. Konekääntämisen ihanteenahan on automatisoida koko käännösprosessi ja siten pyrkiä eroon ihmiskääntäjistä. Kone hoitaa jo nyt ainakin osan tästä prosessista. Lisäksi viime aikoina on otettu huimia harppauksia tekoälyn kehityksen parissa. Ihmislähtöinen kääntäminen tulee siis todennäköisesti katoamaan vielä jonain päivänä. Nykyisen suunnan valossa kysymys on enää siitä, tapahtuuko katoaminen seuraavien vuosien, vuosikymmenten vai vuosisatojen sisällä.